It's hard to overstate how important databases are to modern applications. In particular, we're observing that more and more applications, especially cloud-hosted web service and microservice backends, have little local persistent state and instead store everything in one or more databases or remote data stores. As database researchers, this seems like a big opportunity. Modern cloud-hosted databases, from Aurora to AlloyDB to CockroachDB, are incredibly powerful tools, offering great reliabilility, high availability, and strong transactional semantics. We believe that using these properties, it should be easy to build database-backed applications that are reliable, highly available, and observable.
Right now, though, it isn't. We think the big issue is that infrastructure doesn't know about the database. In other words, there's a missing level of abstraction between how developers write applications, using frameworks like gRPC or Spring Boot and storing state in data stores, and how they deploy applications, using infrastructure like Kubernetes, Fargate, or Lambda which treats the application as a black box and is agnostic to database semantics. This mismatch places the entire burden of managing application state on the developer, causing pain that is especially severe in two areas: reliability and data governance/security.
In terms of reliability, the problem is that developers have to do the hard work of keeping application state consistent. Many applications access multiple data stores and additionally have side effects in external APIs. For example, a (simplified) payment service might make a request to the Stripe API, then record the result in Postgres. For such applications, reliability is really a consistency problem: we must guarantee that the Stripe API call completes and that its result is recorded in Postgres. To do this, as shown below, we have to handle many different types of failure: the application could fail, a database call could fail, or a Stripe API call could fail.
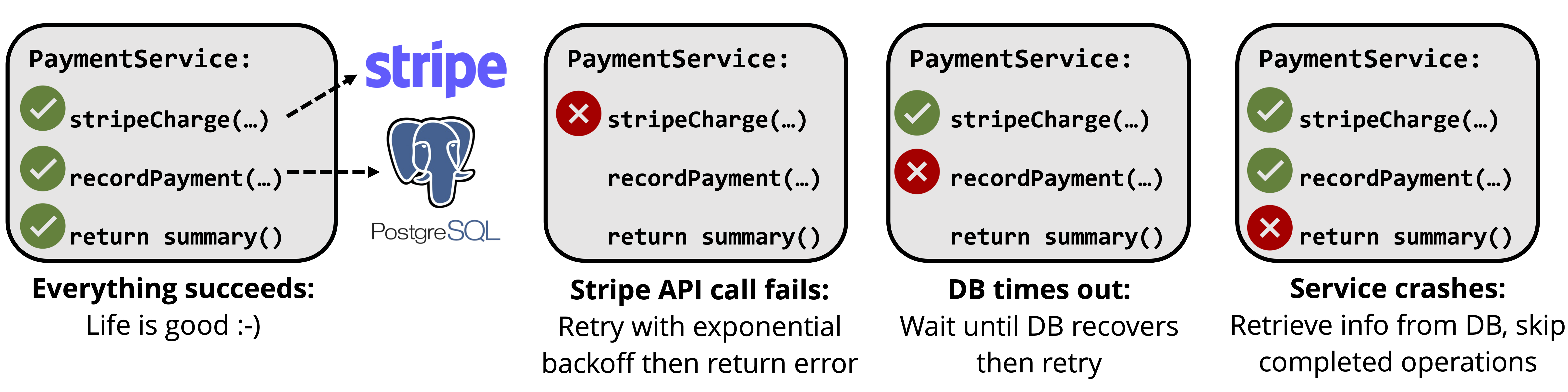
In theory, it should be easy to handle these failures automatically because both Stripe and Postgres provide strong semantics: the Stripe API is idempotent and Postgres is transactional. In practice though, developers have to write custom retry and recovery logic for each application, which is difficult and gets more difficult as applications get more complex. We've heard that many teams essentially have to build their own distributed fault-tolerant state machines on top of Kafka or SQS, which shouldn't be (but currently is) necessary for a simple payment processing application.
In terms of governance and security, the problem is that it's hard to track who does what to application state and data. This has become especially important over the last few years. Laws like GDPR and CCPA impose strict requirements on what applications can do with data, for example requiring that personally identifiable information (PII) is only used for well-defined purposes or is only stored in data centers physically located in certain countries. In our earlier payment service example, regulation might say that recorded payment information can only be used in the payment service and cannot be accessed for, say, marketing purposes. In theory, if the application stores all its data in the database and PII and purposes are annotated, then the application infrastructure should be able to enforce these requirements automatically. In practice, though, most infrastructure does not support this and developers have to write custom complex data observability layers that change with each new standard.
To solve problems like these, we've been researching how to build systems and infrastructure that are more aware of the database as part of the DBOS project at Stanford and MIT. We've built or are building systems such as a database-oriented function-as-a-service platform (Apiary: arXiv, GitHub), a new cross-data store transactions protocol, and a transaction-oriented debugger (CIDR '23). The reason we're writing this blog post is because we want to learn from you, developers who encounter these problems in the real world, about where to go next. Based on our research, we think it's possible to build new abstractions between applications and deployment infrastructure so that:
- Reliability is easy. You can make a request or call a function with an automatic infrastructure-backed guarantee that any side effects it has on state (whether in a data store or in external APIs, though the latter may need to be annotated) happen exactly-once.
- Data governance and security are built-in. The infrastructure automatically tracks the provenance of each data item—which operations read from and wrote to it—and makes this information easily accessible for debugging, regulatory compliance, and security analysis.
- How true are our hypotheses? Do your applications store all (or almost all) their persistent state in one or more databases or data stores?
- Are the problems we're describing serious? How much time do you spend on issues related to data consistency and application reliability? What about data governance and security?
- How do you currently solve these problems? How hard are these solutions to implement? What problems are especially hard to solve?
- What are we missing?

